AI is only as good
as the data it runs on.
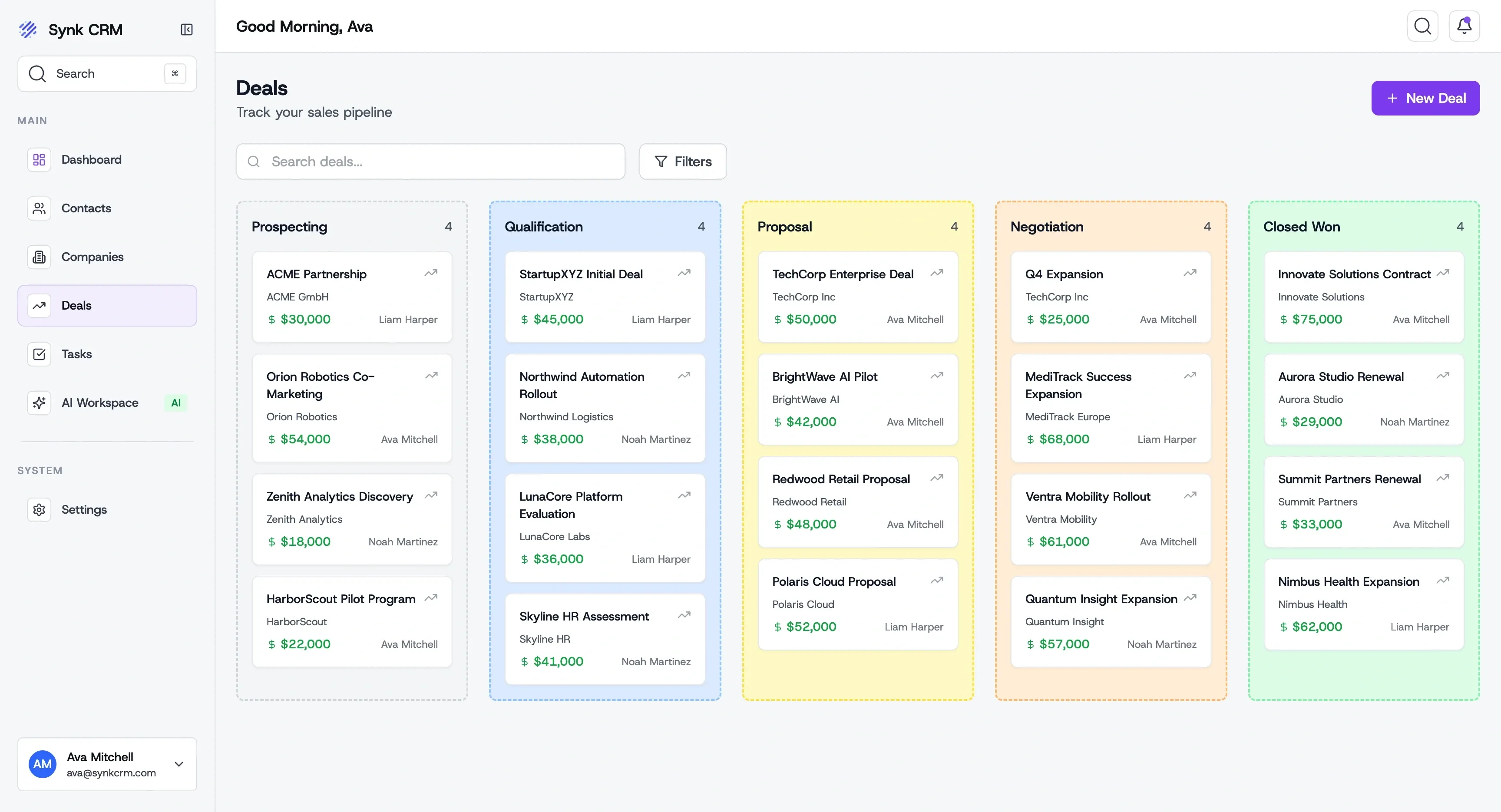
Most AI systems fail not because of the model but because of messy, fragmented, inconsistent data. Golden Pipelines and Custom Data Models transform raw enterprise data into structured, governed, AI-ready systems designed for production.
Turning Messy Data Into Reliable AI Applications
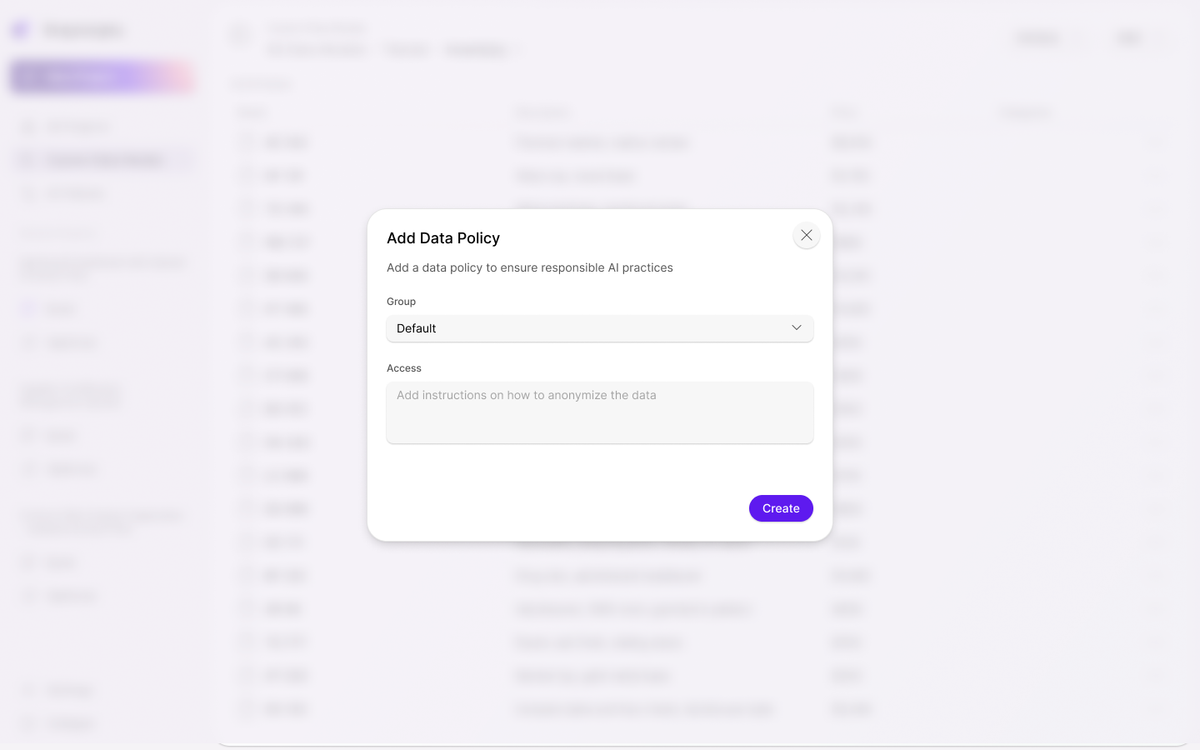
Unified Data Ingestion
Structured or Unstructured Data
Ingest structured and unstructured data from files, APIs, databases, and documents into a consistent execution path.
Automated Cleaning & Normalization
Automated Cleaning & Normalization
Detect duplicates, inconsistencies, missing fields, and formatting conflicts before data reaches inference.
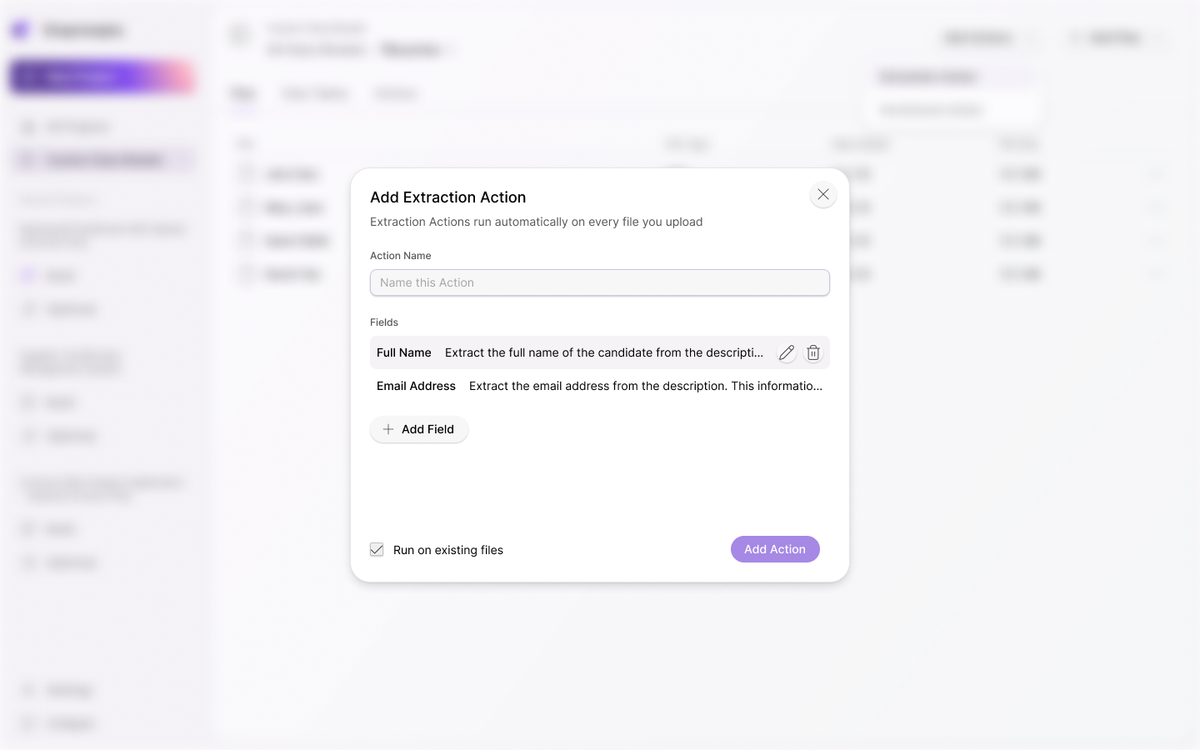
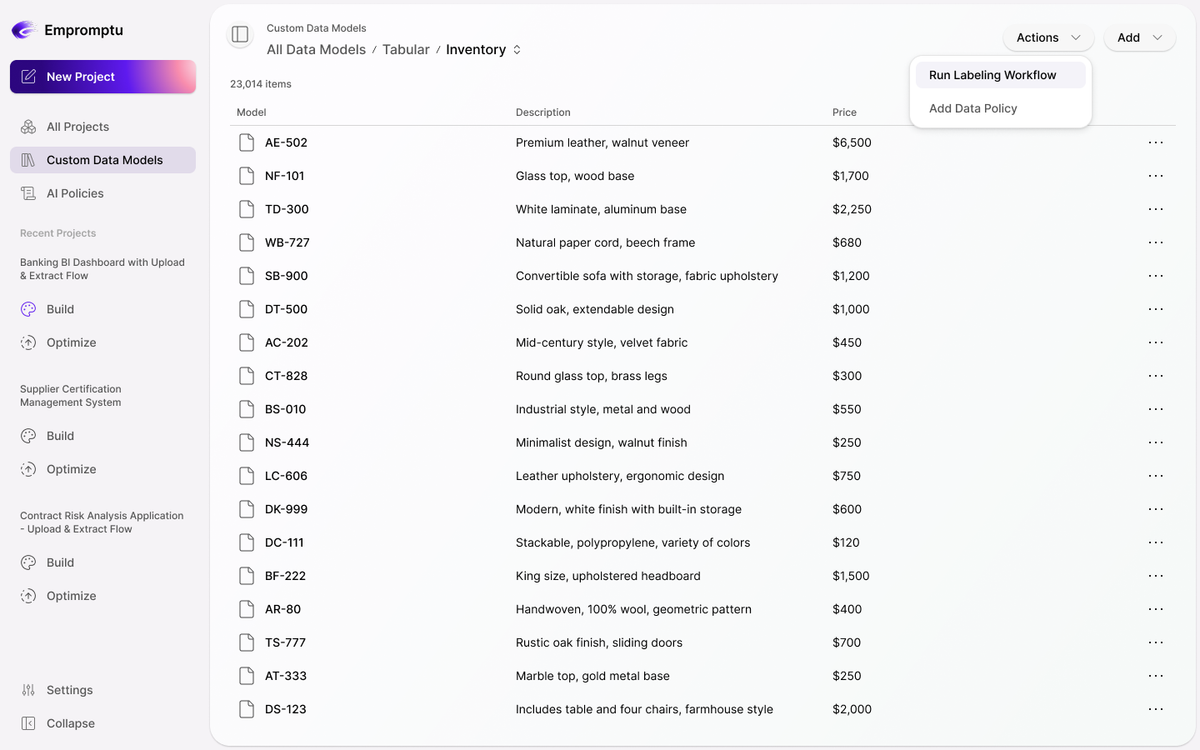
Domain-Aware Custom Data Models
Custom Data Models
Define entities, relationships, and constraints explicitly so AI systems reason from structured knowledge instead of pattern-matching text.
Agentic Data Enrichment
Agentic Data Enrichment
Generate missing classifications, labels, or contextual fields to improve accuracy and reduce edge-case failure
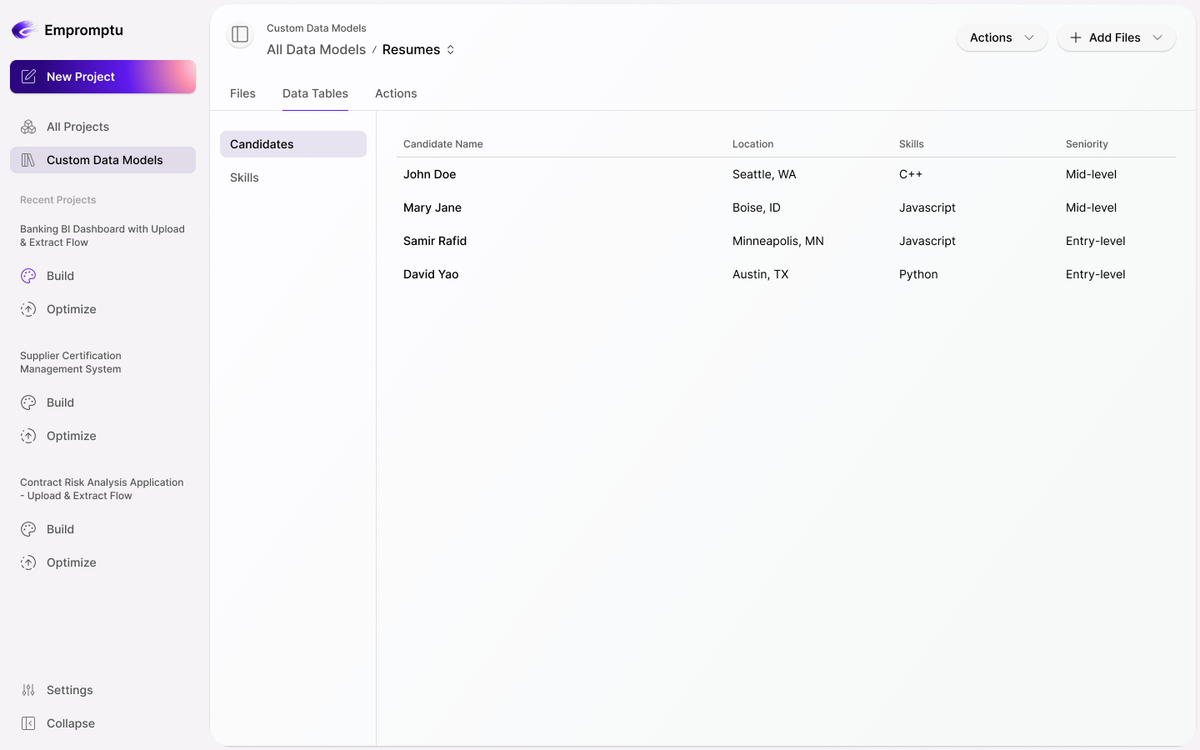
Enterprise AI Applications That Depend on Messy Operational Data
Golden Pipelines and Custom Data Models are designed for environments where real-world data is incomplete, inconsistent, and constantly evolving.
Industry-Specific Platforms
Model domain entities and relationships explicitly to support vertical AI applications.
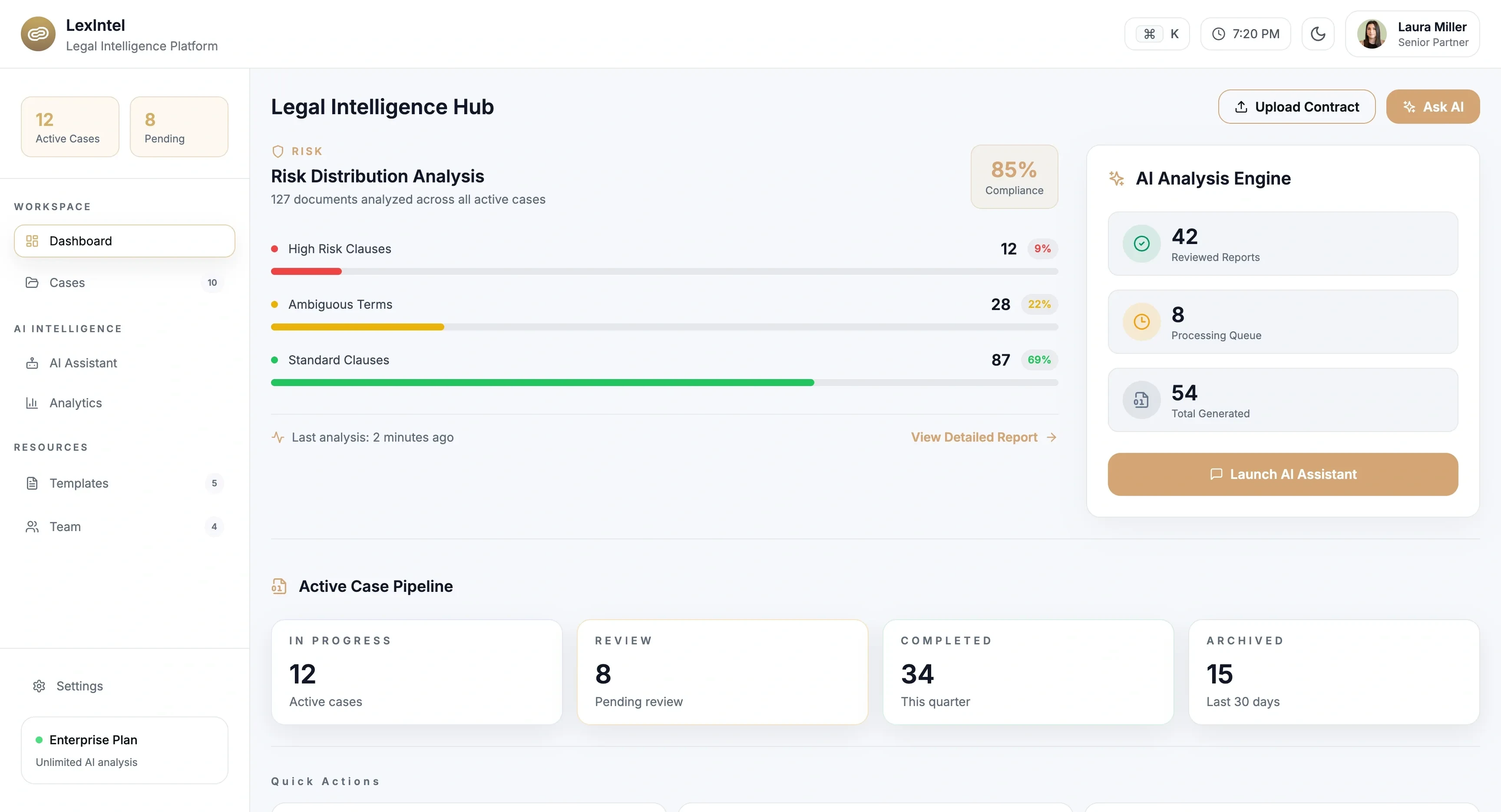
Customer-Facing AI Workflows
Ensure outputs remain consistent and reliable even as input variability increases.
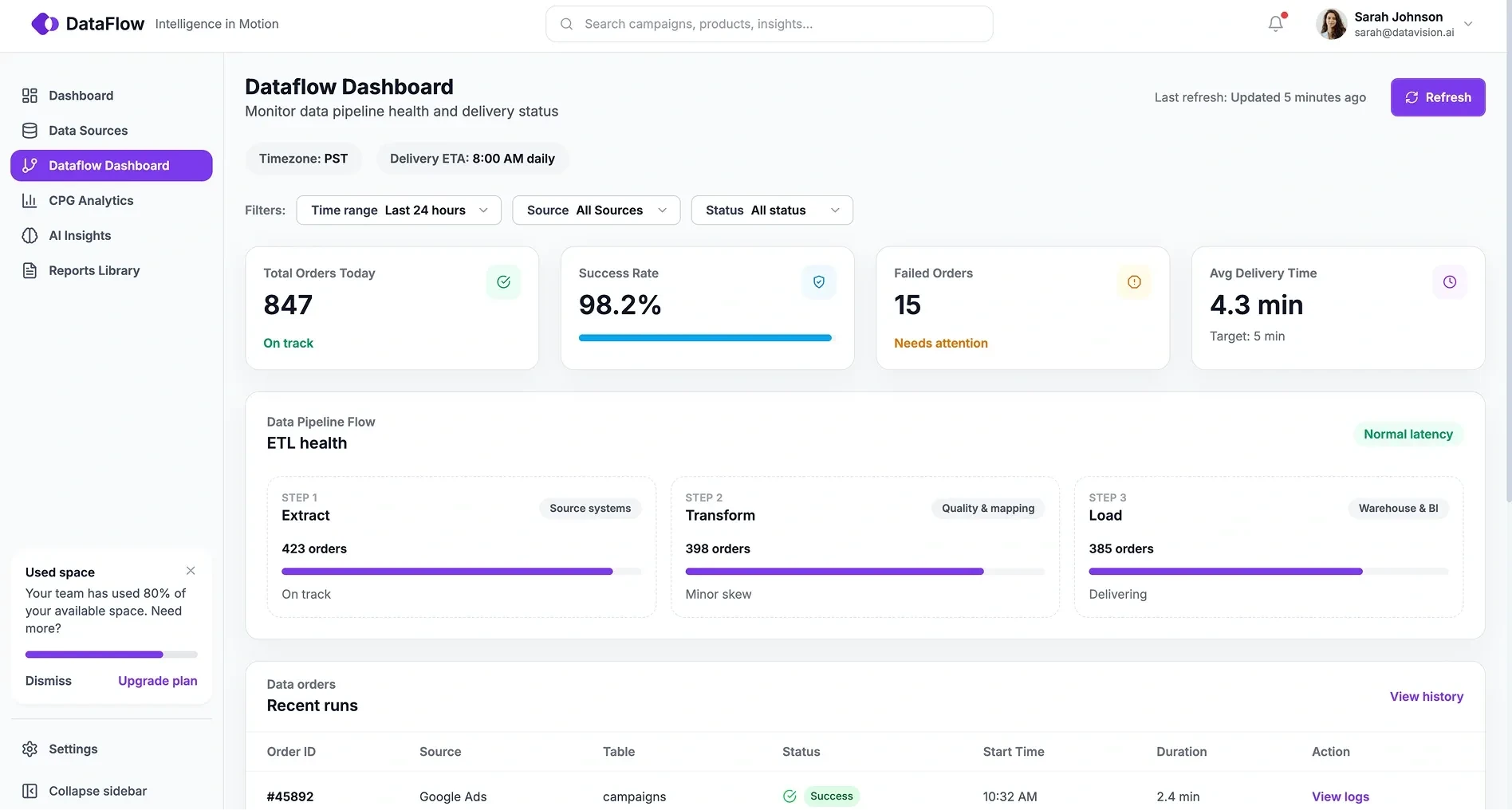
AI-Powered SaaS Extensions
Extend existing platforms with AI features powered by normalized operational data.